Analiza tematyczna danych TIMSS za pomocą IEA IDB Analyzer
Ocena związku płci, kraju, lokalizacji szkoły i statusu społeczno-ekonomicznego z wynikiami w zakresie biologii i rozumowania matematycznego. W poradniku wykorzystano statystyki opisowe i analizę regresji liniowej.
1 Wprowadzenie
Ten dokument przedstawia przygotowanie i analizę zestawu danych TIMSS 2023 (Trends in International Mathematics and Science Study 2023) przy użyciu IEA IDB Analyzer. Badanie TIMSS jest przeprowadzane co 4 lata i ma na celu ocenę umiejętności z zakresu matematyki i nauk przyrodniczych uczniów klas 4 i 8.
Przedstawiona tutaj analiza koncentruje się na różnicach z zakresu rozumowanania matematycznego i biologii, według kraju i płci.
Rozumowanie matematyczne jest poddziedziną szerszego obszaru umiejętności z zakresu matematyki a biologia jest poddziedziną szerszego obszaru umiejętności z zakresu nauk przyrodniczych.
W poradniku wykorzystano również regresję liniową do zbadania:
związku między wielkością miasta/wsi, w której zlokalizowana jest szkoła a wynikami rozumowania matematycznego;
związku między statusem społeczno-ekonomicznym (SES) a wynikami z zakresu biologii;
Skupimy się na uczniach klas 4 z Polski, Niemiec, Gruzji i Nowej Zelandii.
Więcej informacji o pakiecie IEA IDB Analyzer można znaleźć w naszym tutorialu.
2 Pobieranie i łączenie danych
Najpierw należy pobrać dane ze strony www.iea.nl/data-tools/repository/timss.
W zależności od oprogramowania, którego chcesz użyć do uruchomienia skryptów wygenerowanych przez IEA IDB Analyzer, należy pobrać dane w odpowiednim formacie (np. R lub SPSS).
Ten poradnik wykorzystuje język R, więc pobierzemy dane w formacie R i zapiszemy je w wybranym katalogu.
Zmienne, na których się skupimy to:
IDCNTRY- Nazwa krajuITSEX- płeć uczniówASBHSES- indeks statusu społeczno-ekonomicznego rodziny uczniaACGB05B- wielkość wsi/miasta, w którym znajduje się szkołaASMREA01-ASMREA05- wynik rozumowania matematycznegoASSLIF01-ASSLIF05- wynik z zakresu biologii
Użyjemy modułu łączenia danych (merge module) IEA IDB Analyzer, aby utworzyć zestaw danych ze zmiennymi wymienionymi powyżej.
Najpierw wybierzemy kraje będące przedmiotem zainteresowania (Polska, Niemcy, Gruzja i Nowa Zelandia).
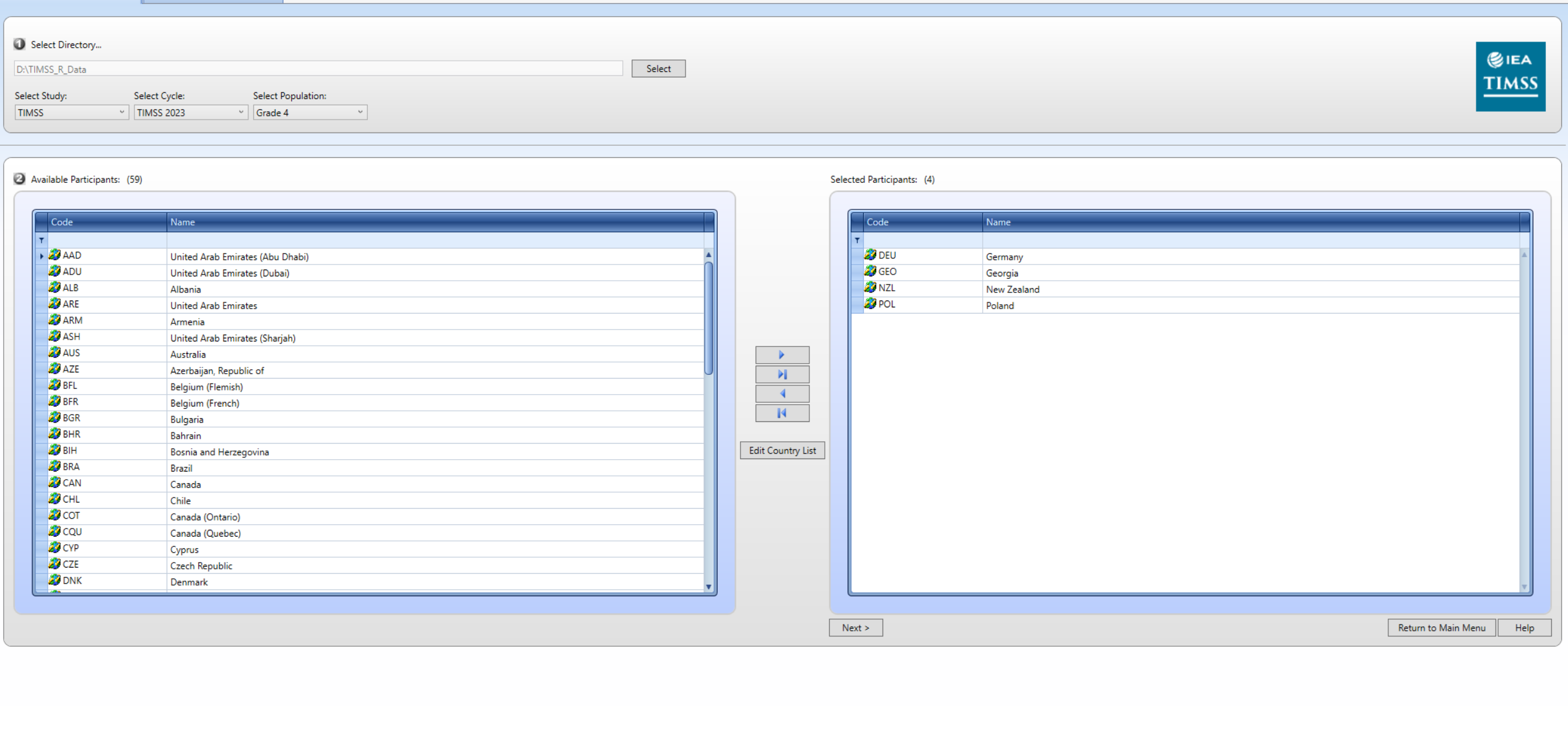
Następnie wybierzemy bazy danych i zmienne będące przedmiotem zainteresowania.
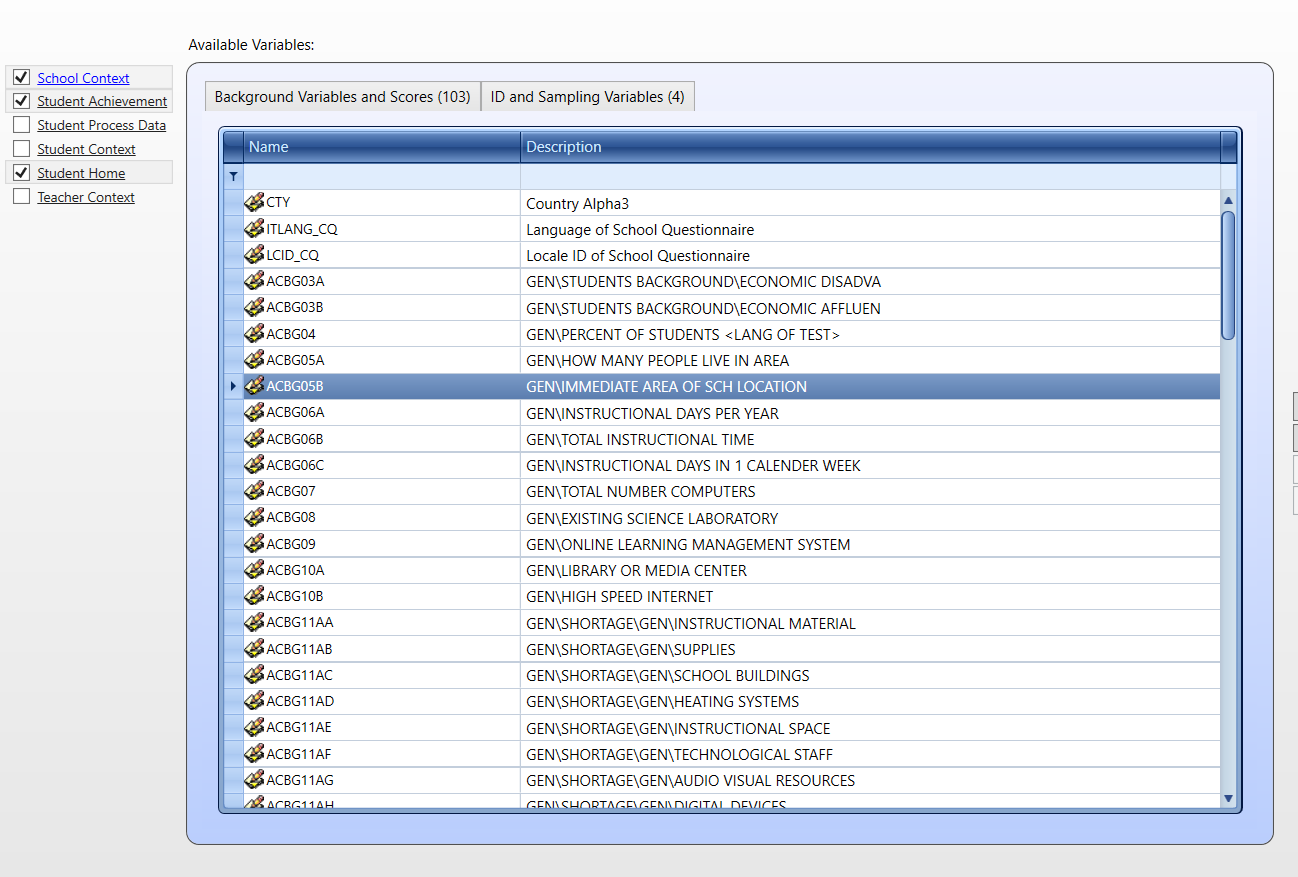
Musimy wybrać następujące bazy danych: School Context, Student Achievement oraz Student Home.
Z bazy danych School Context wybierzemy zmienną ACGB05B (wielkość miejscowości, w której znajduje się szkoła).
Z zestawu danych Student Home wybierzemy zmienną ASBHSES (status społeczno-ekonomiczny domu).
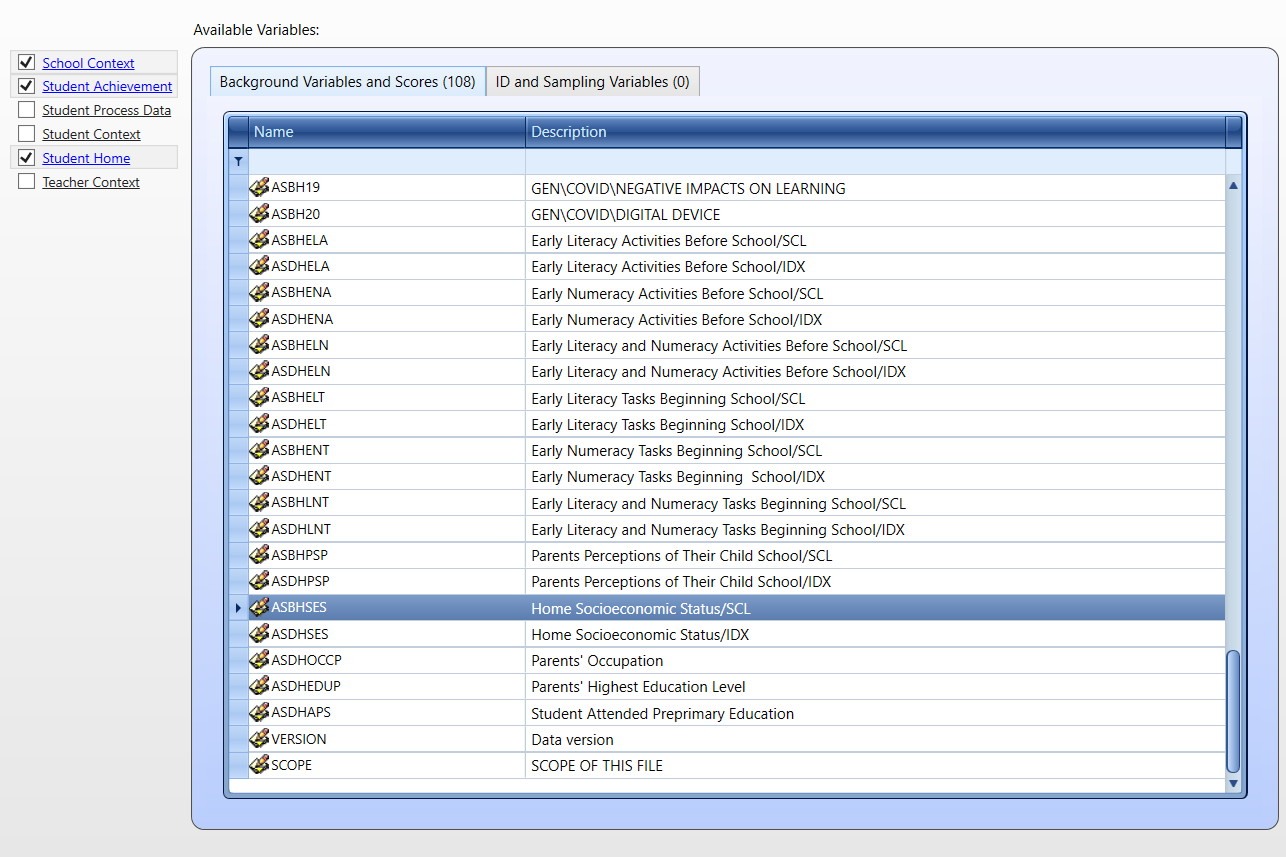
Następnie musimy zapisać skrypt R i uruchomić go w RStudio lub innym środowisku dla R.
3 Statystyki opisowe
Po uruchomieniu skryptu możemy wrócić do głównego menu IEA IDB Analyzer i wybrać moduł analizy (analysis module).
Następnie należy wybrać zestaw danych utworzony w poprzednim kroku, wybrać TIMSS (Using Student Weights) jako typ analizy i Percentages and Means jako typ statystyki. Pozostałe opcje należy pozostawić domyślne.

Chcemy rozdzielić tabele według płci i użyć wartości prawdopodobnych wyników rozumowania matematycznego i wyników z zakresu biologii. Wagi replikacyjne są dodawane automatycznie.
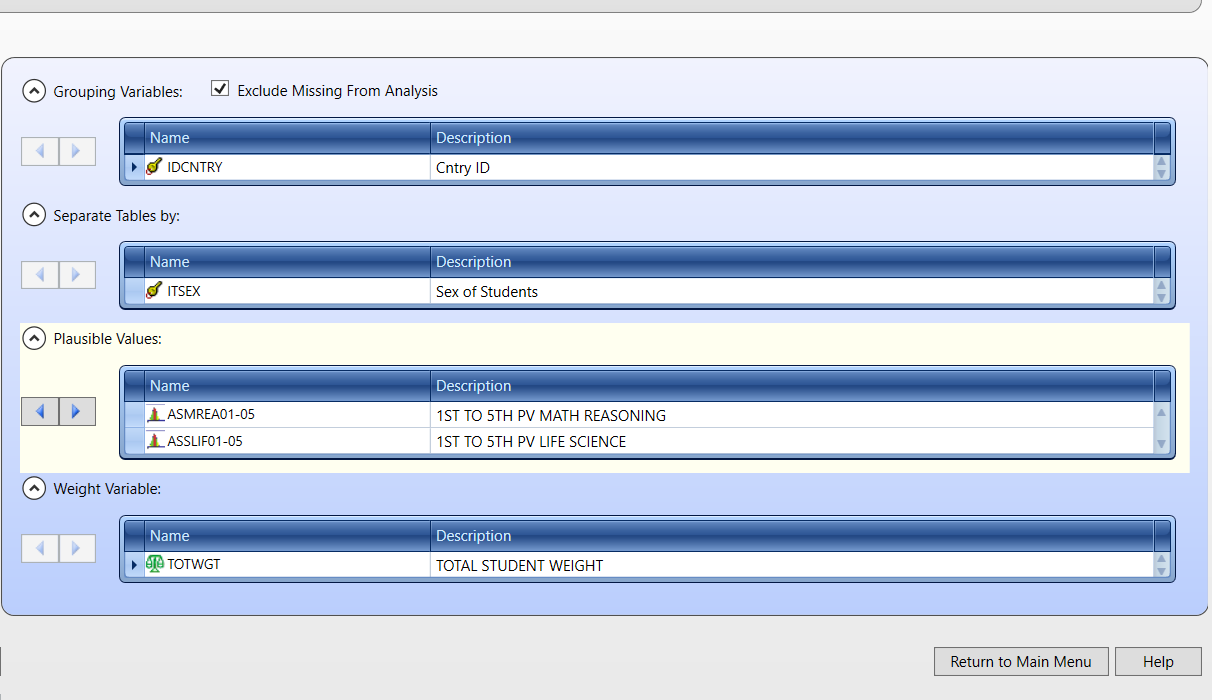
Następnie należy zapisać skrypt R i uruchomić go. Ponieważ chcieliśmy przeprowadzić analizę dla dwóch zmiennych, otrzymamy dwa raporty. Raporty w formacie .html powinny otworzyć się automatycznie, gdy R zakończy wykonywanie skryptu.
W pliku .html należy przewinąć do sekcji Report, aby zobaczyć wyniki. Najpierw przyjrzyjmy się wynikom dla rozumowania matematycznego.
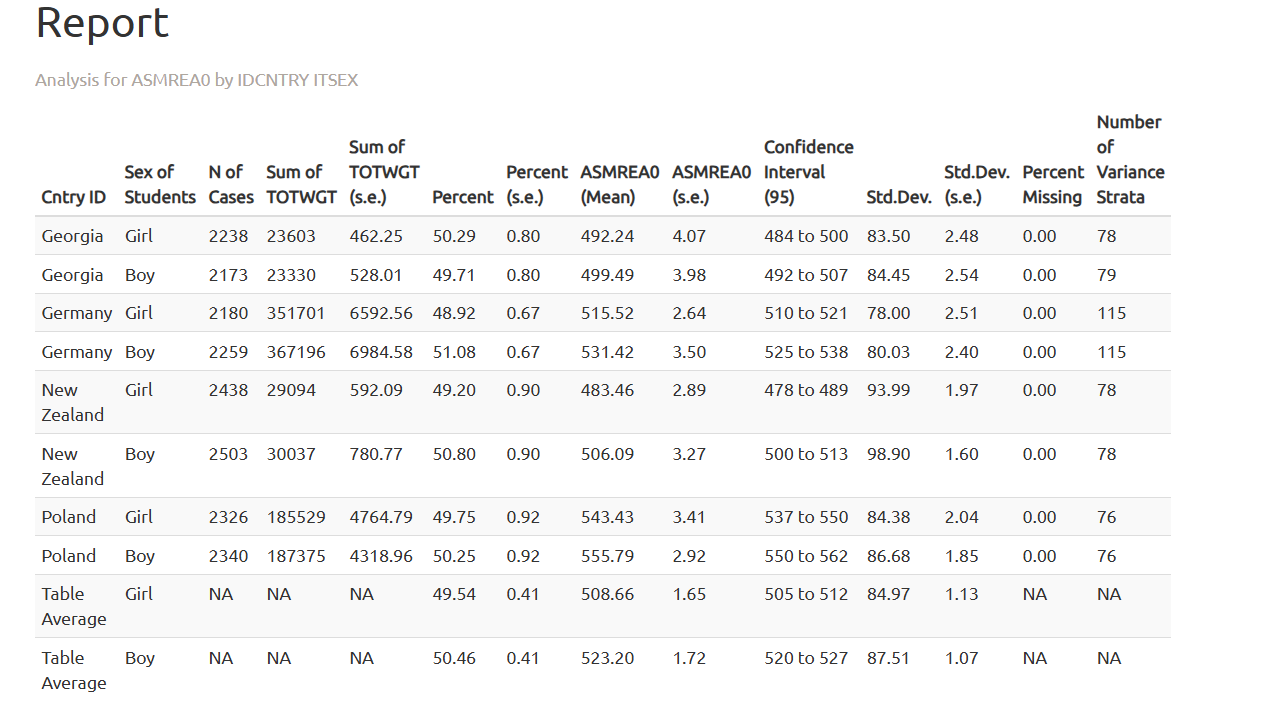
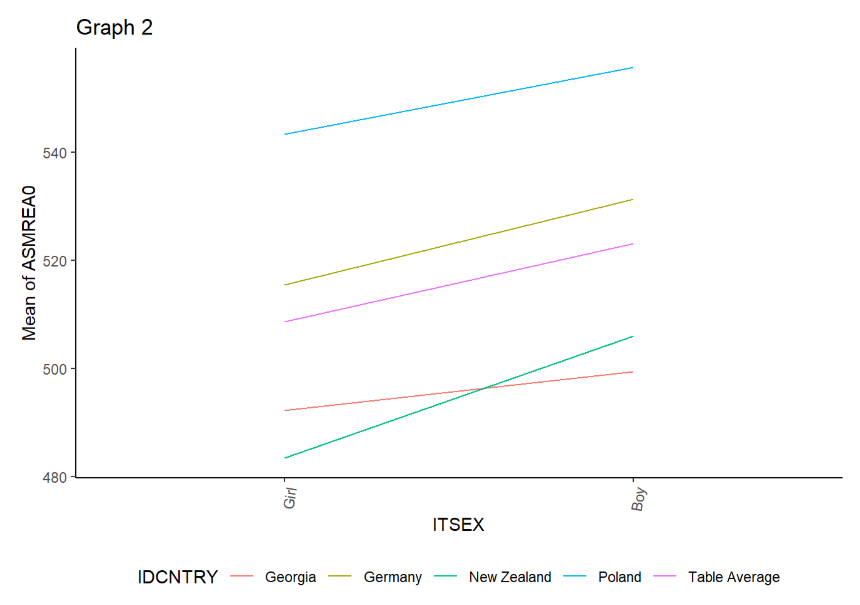
Następnie obejrzymy wyniki dla umiejętności z zakresu biologii.
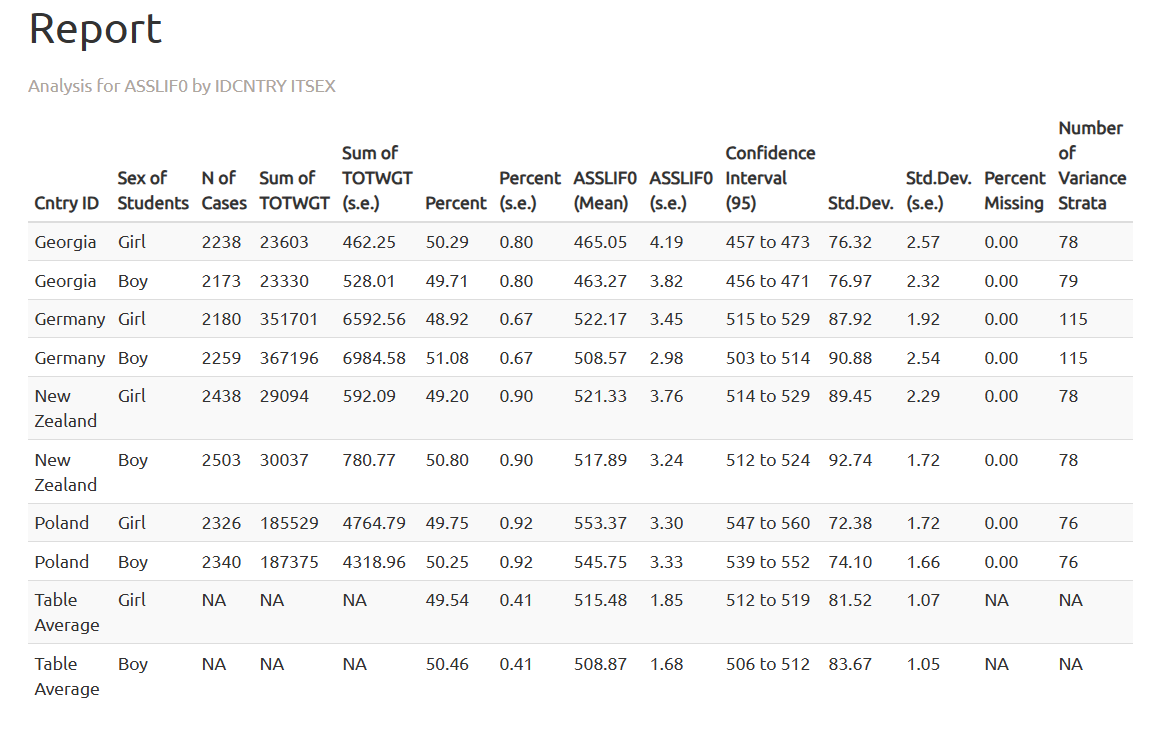
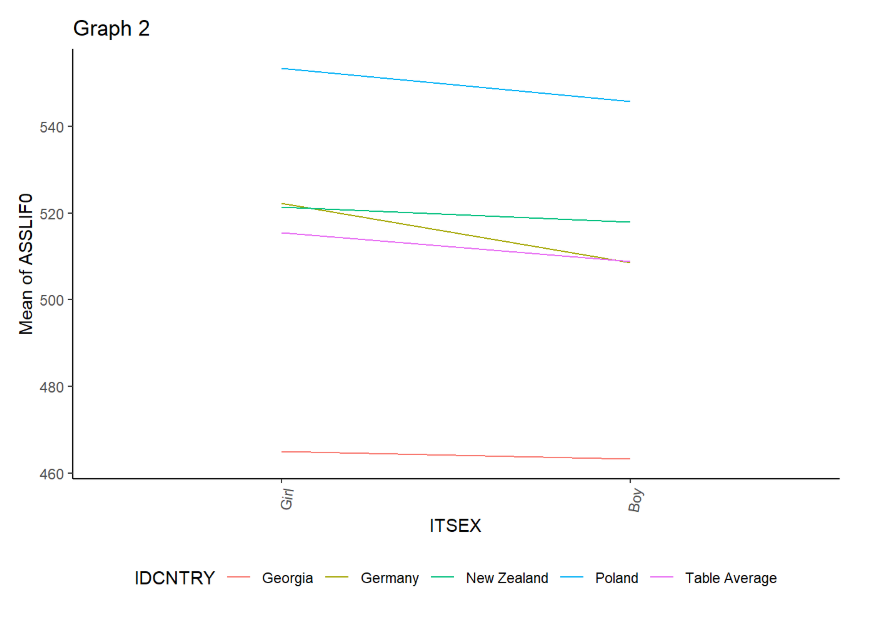
4 Wielkość miejscowości szkoły a wyniki rozumowania matematycznego
Teraz wrócimy do modułu analizy (analysis module) IEA IDB Analyzer i wybierzemy TIMSS (Using Student Weights) jako typ analizy i Linear Regression jako typ statystyki.
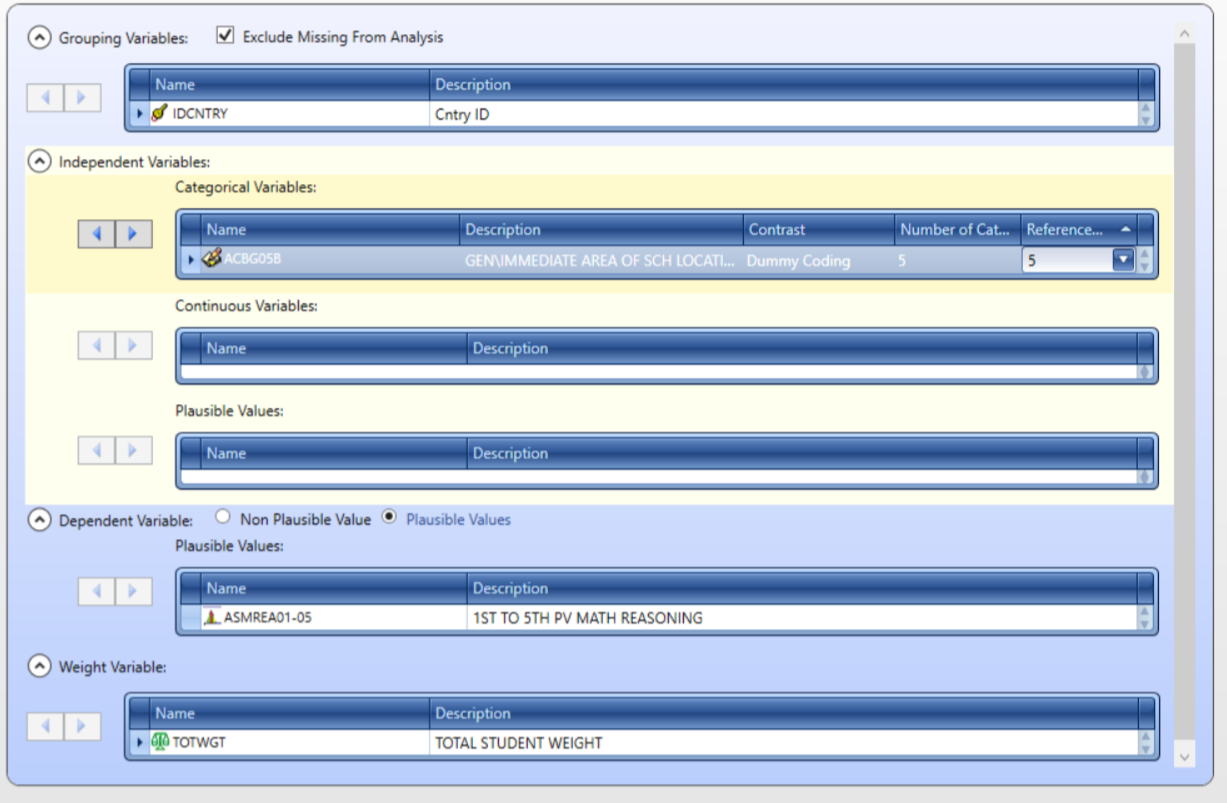
Wybierzemy wartości prawdopodobne rozumowania matematycznego jako zmienną zależną i wielkość miejscowości szkoły (ACGB05B) jako zmienną niezależną.
Jest to zmienna kategoryczna z 5 poziomami:
1- Miejski – gęsto zaludniony2- Podmiejski – na obrzeżach lub peryferiach obszaru miejskiego3- Średniej wielkości miasto lub duże miasteczko4- Małe miasteczko lub wieś5- Odległy obszar wiejski
Musimy zmienić liczbę kategorii na 5 i wybrać 5 jako kategorię referencyjną.
Podobnie jak poprzednio, zapiszemy skrypt R, uruchomimy go i przeanalizujemy wyniki w sekcji Report pliku .html.
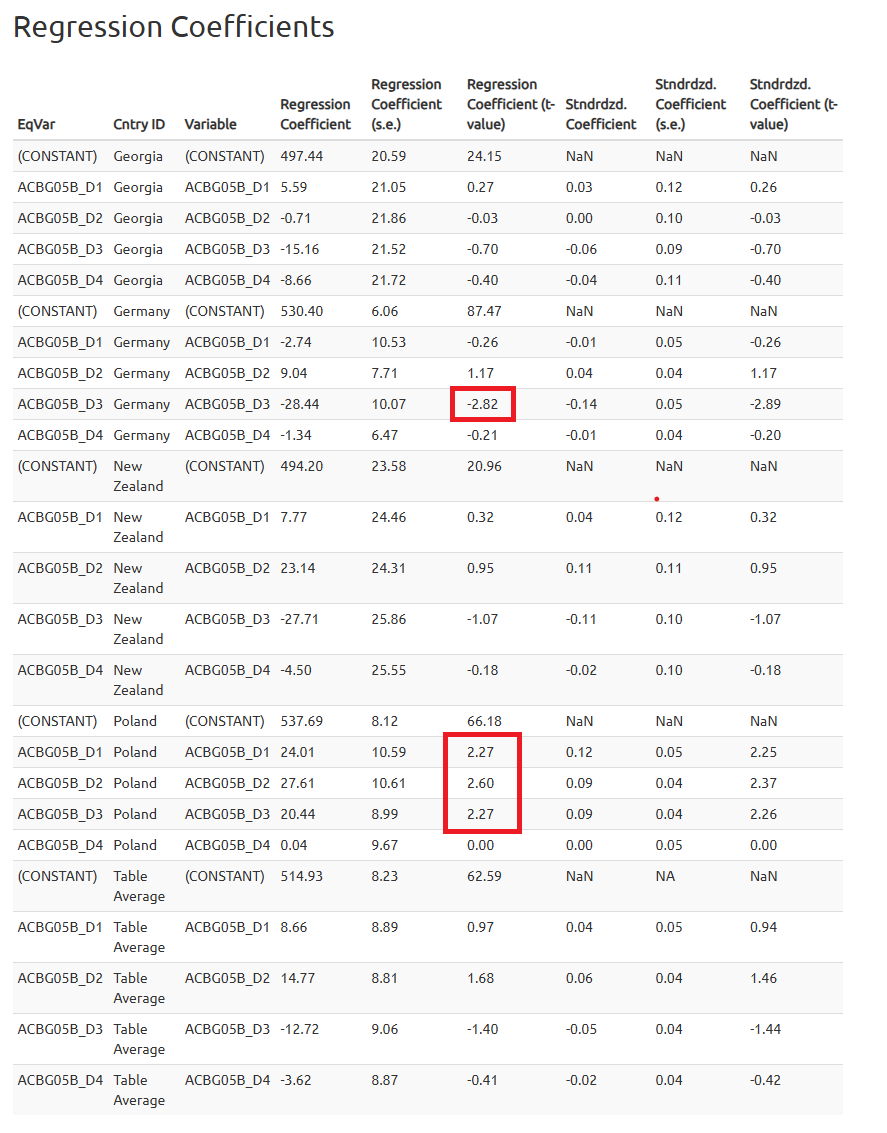
Aby określić, czy predyktor jest istotny, powinniśmy przyjrzeć się wartości t w tabelach regresji.
Wartości t większe niż 1,96 (w wartości bezwzględnej) wskazują, że predyktor jest statystycznie istotny na poziomie istotności 0,05.
5 Status społeczno-ekonomiczny a wyniki z zakresu biologii
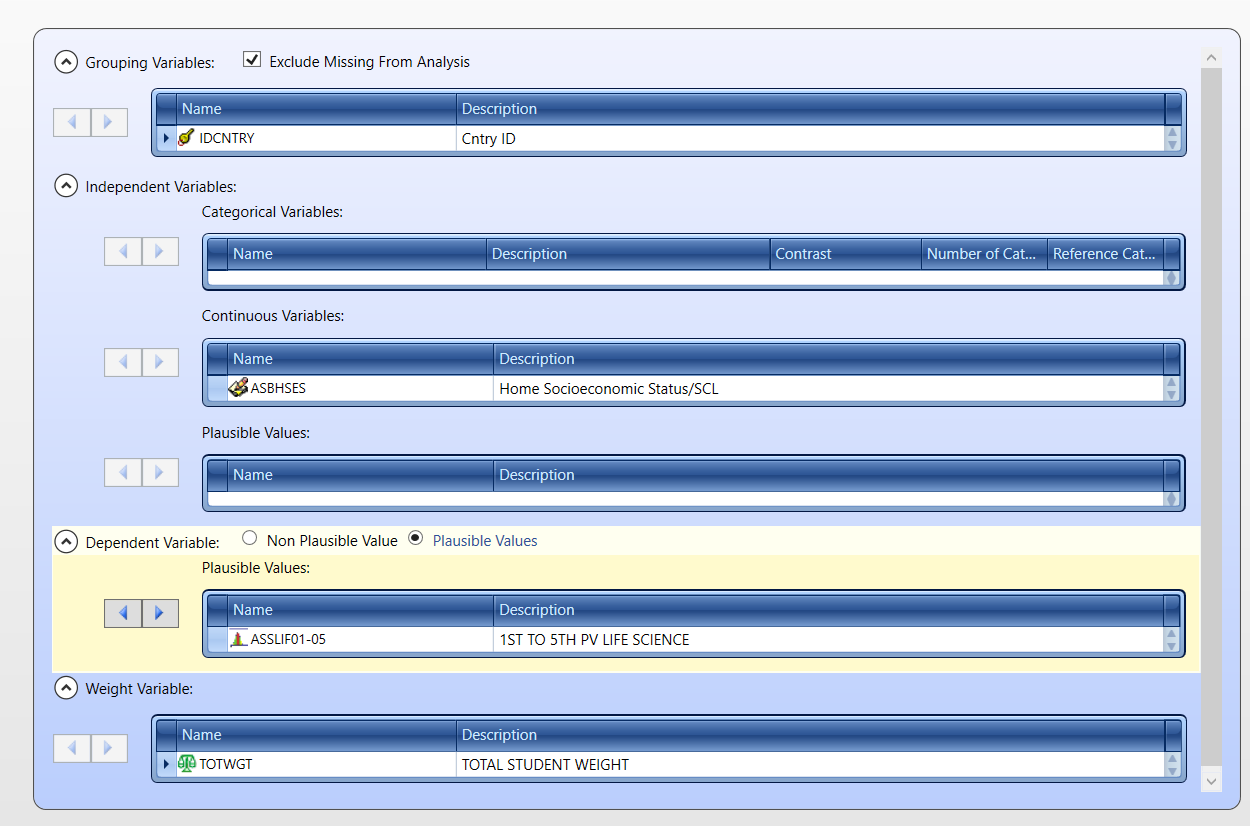
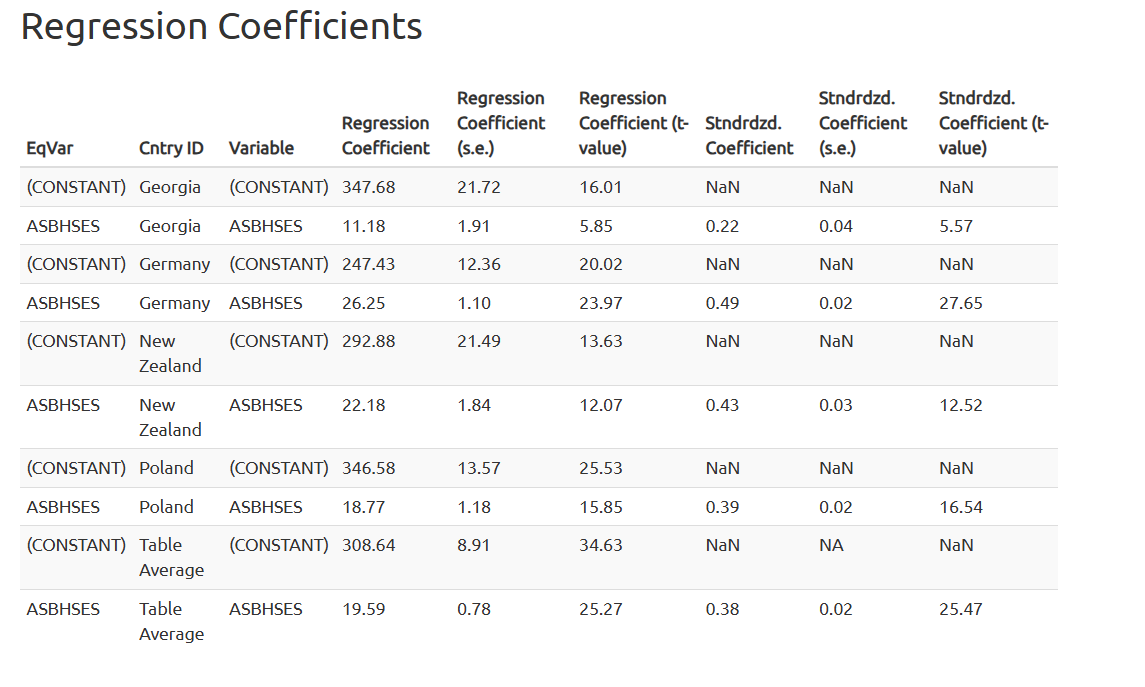
Na koniec zbadamy związek między statusem społeczno-ekonomicznym (SES) a wynikami w zakresie biologii.
Definicja analizy jest podobna do poprzedniej. SES powinien być dodany do analizy jako predyktor ciągły.
W badaniu TIMSS 2023 istnieją dwie zmienne związane z domowym statusem społeczno-ekonomicznym:
- ASBHSES - status społeczno-ekonomiczny/SCL (zmienna ciągła); - ASDHSES - status społeczno-ekonomiczny/IDX (zmienna kategoryczna);
Do analizy regresji użyjemy zmiennej ciągłej (ASBHSES), niemniej zmienna kategoryczna (ASDHSES) może być również użyta w tej analizie podobnie do analizy regresji z lokalizacją szkoły jako predyktorem.
6 Podsumowanie
Ten dokument pokazuje, jak przygotować i analizować zestaw danych TIMSS 2023 przy użyciu IEA IDB Analyzer. Omówiliśmy łączenie danych za pomocą IEA IDB Analyzer, obliczenie statystyk opisowych i przeprowadzenie analiz regresji z uwzględnieniem złożonego projektu badania. Wyniki dostarczyły wglądu w różnice w wynikach w zakresie biologii i rozumowania matematycznego według kraju, płci, wielkości miejsca zamieszkania i statusu społeczno-ekonomicznego.